Object detection
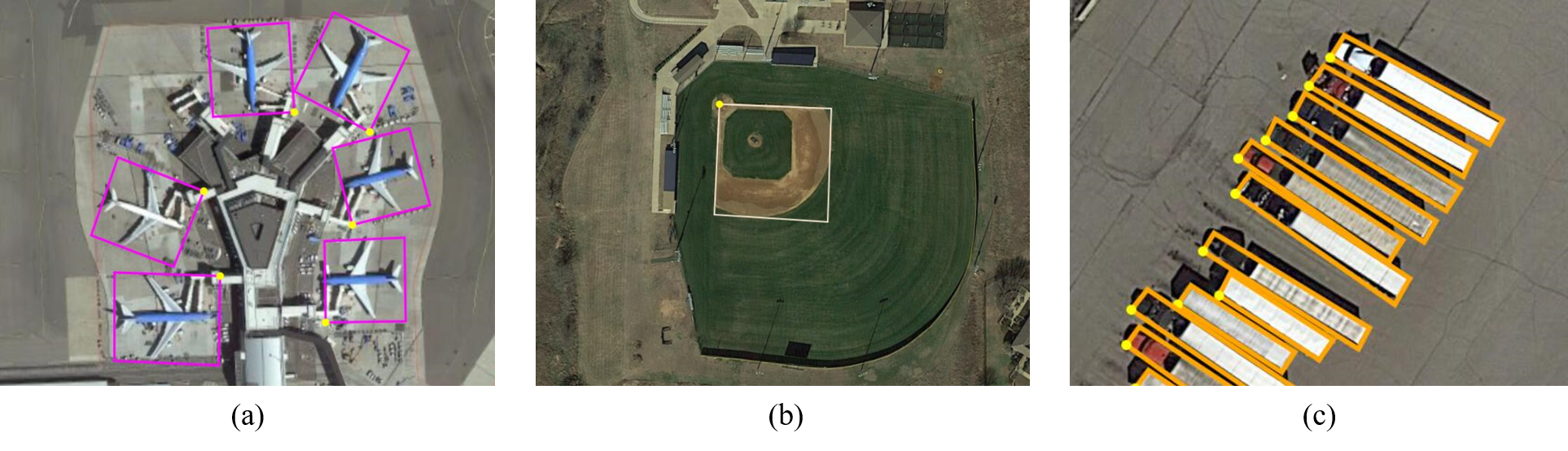
Object detection track is based on DOTA-v2.0. DOTA-v2.0 collects more Google Earth, GF- 2 Satellite, and aerial images. There are 18 common categories, 11,268 images and 1,793,658 instances in DOTA-v2.0. Compared to DOTA-v1.5, it further adds the new categories of ”airport” and ”helipad”. The 11,268 images of DOTA are split into training, validation, test-dev, and test-challenge sets. To avoid the problem of overfitting, the proportion of the training and validation set is smaller than the test set. Furthermore, we have two test sets, namely test-dev and test-challenge. Training contains 1,830 images and 268,627 instances. Validation contains 593 images and 81,048 instances. We released the images and ground truths for training and validation sets. Test-dev contains 2,792 images and 353,346 instances. We released the images but not the ground truths. Test-challenge contains 6,053 images and 1,090,637 instances. The images and ground truths of the test-challenge will be available only during the challenge. In the dataset, each instance's location is annotated by a quadrilateral bounding box, which can be denoted as "x 1, y 1, x 2, y 2, x 3, y 3, x 4, y 4" where (x i, y i) denotes the positions of the oriented bounding boxes' vertices in the image. The vertices are arranged in clockwise order. The following is the visualization of the adopted annotation method. The yellow point represents the starting point. Which refers to: (a) the top left corner of a plane, (b) the top left corner of a large vehicle diamond, (c) the center of sector-shaped baseball.
Except for the annotation of location, a category label is assigned for each instance, which comes from one of the above 15 selected categories, and meanwhile, a difficult label is provided which indicates whether the instance is difficult to be detected(1 for difficult, 0 for not difficult). Annotations for an image are saved in a text file with the same file name. In the first line, 'imagesource'(from GoogleEarth, GF-2 or JL-1) is given. In the second line, ’gsd’(ground sample distance, the physical size of one image pixel, in meters) is given. Note if the 'gsd' is missing, it is annotated to be 'null'. From the third line to the last line in the annotation text file, the annotation for each instance is given. The annotation format is:
'gsd':gsd
x 1, y 1, x 2, y 2, x 3, y 3, x 4, y 4, category, difficult
x 1, y 1, x 2, y 2, x 3, y 3, x 4, y 4, category, difficult
...
Semantic Segmentation
Semantic segmentation track is based on GID15. GID15 is a new large-scale land-cover dataset with Gaofen-2 (GF-2) satellite images. This new dataset, which is named as Gaofen Image Dataset with 15 categories (GID-15), has superiorities over the existing land-cover dataset because of its large coverage, wide distribution, and high spatial resolution. The large-scale remote sensing semantic segmentation set contains 150 pixel-level annotated GF-2 images, which is labeled in 15 categories. The annotated examples are shown as follows:
